Workshop Notes (August 27, 2016): End-to-End Streaming ML Recommendation Pipeline (Spark 2.0, Kafka, TensorFlow)
August 27, 2016
9:00 AM – 5:00 PM

From the promotional materials:
END-TO-END STREAMING ML RECOMMENDATION PIPELINE WORKSHOP
Learn to build an end-to-end, streaming recommendations pipeline using the latest streaming analytics tools inside a portable, take-home Docker Container in the cloud!
DATE Saturday, August 27, 2016
TIME 9:00 AM Central Standard Time
VENUE 2.03 Classroom
You’ll learn how to:
- Create a complete, end-to-end streaming data analytics pipeline
- Interactively analyze, approximate, and visualize streaming data
- Generate machine learning, graph & NLP recommendation models
- Productionize our ML models to serve real-time recommendations
- Perform a hybrid on-premise and cloud deployment using Docker
- Customize this workshop environment to your specific use cases
Agenda:
Part 1 (Analytics and Visualizations)
- Analytics and Visualizations Overview (Live Demo!)
- Verify Environment Setup (Docker)
- Notebooks (Zeppelin, Jupyter/iPython)
- Interactive Data Analytics (Spark SQL, Hive, Presto)
- Graph Analytics (Spark Graph, NetworkX, TitanDB)
- Time-series Analytics (Cassandra)
- Visualizations (Kibana, Matplotlib, D3)
- Approximate Queries (Spark SQL, Redis, Algebird)
- Workflow Management (AirFlow)
Part 2 (Streaming and Recommendations)
- Streaming and Recommendations Overview (Live Demo!)
- Streaming (NiFi, Kafka, Spark Streaming, Flink)
- Cluster-based Recommendation (Spark ML, Scikit-Learn)
- Graph-based Recommendation (Spark ML, Spark Graph)
- Collaborative-based Recommendation (Spark ML)
- NLP-based Recommendation (CoreNLP, NLTK)
- Geo-based Recommendation (ElasticSearch)
- Hybrid On-Premise+Cloud Auto-Scale Deploy (Docker)
- Customize the Workshop Environment for Your Use Cases
Target Audience:
- Interest in learning more about the streaming data pipelines that power their real-time machine learning models and visualizations
- Interest in building more intuition about machine learning, graph processing, natural language processing, statistical approximation techniques, and visualizations
- Interest in learning the practical applications of a modern, streaming data analytics and recommendations pipeline
- Anyone who wants to try 3D-printed PANCAKES!!
Prerequisites:
- Basic familiarity with Unix/Linux commands
- Experience in SQL, Java, Scala, Python, or R
- Basic familiarity with linear algebra concepts (dot product)
- Laptop with an ssh client and modern browser
- Every attendee will get their own fully-configured cloud instance running the entire environment
- At the end of the workshop, you will be able to save and download your environment to your local laptop in the form of a Docker image
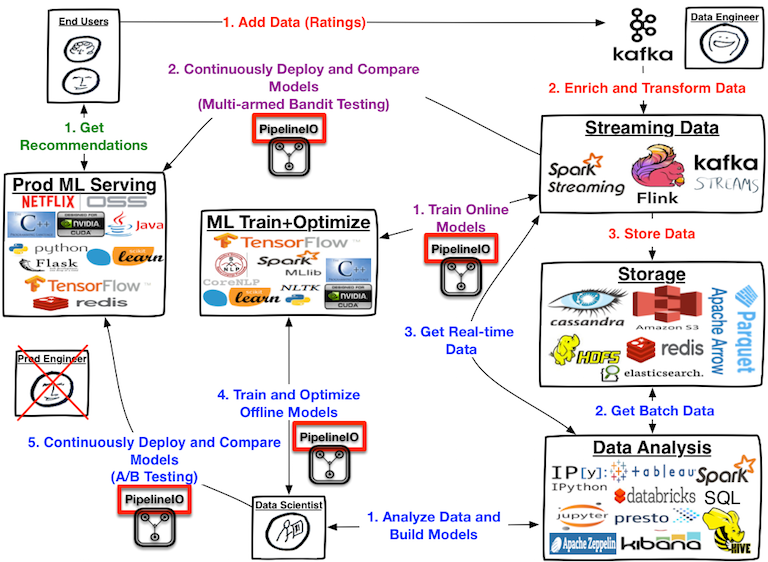
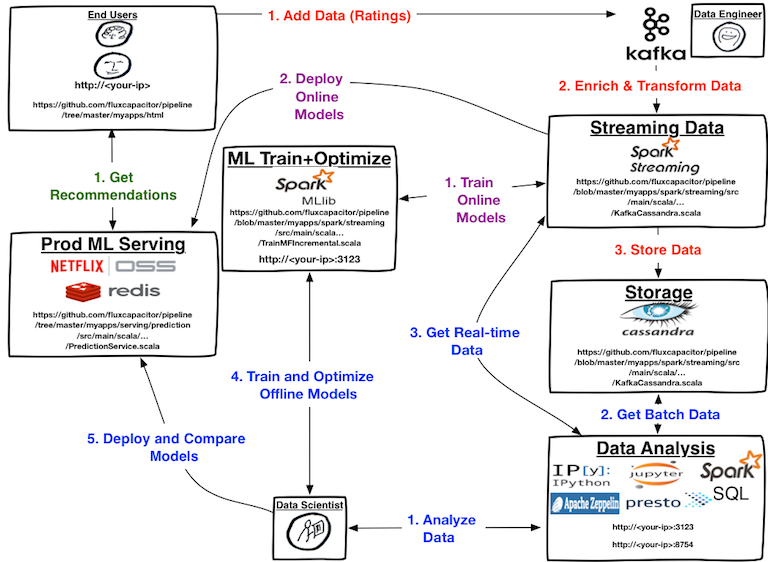
My personal notes:
- the workshop description can be found at this link
- there were between 80 and 90 attendees to this event
- Chris had originally booked another location, but moved to 1871 due to the demand
This post is for subscribers only
Already have an account? Sign in.